Salesforce内の件数の多いオブジェクトに対して、データの取得/登録/更新/削除を行う場合、通常のAPIのinsert/update/upsert/deleteでは時間がかかってしまうことがあります。
Salesforceでは、これに対してBulk API/Bulk API2.0を用意しており、Bulk API2.0について調べた結果の備忘メモです。
Bulk API2.0でのクエリの処理
1.クエリジョブの作成 (/services/data/vXX.X/jobs/query)
SOQLや、query/queryAllかなどを指定したjson文字列を送信(POST)
2.クエリジョブに関する情報の取得(/services/data/vXX.X/jobs/query/queryJobId)
クエリジョブの状況を取得(GET)。状況(state)がInProgressならば、しばらく待って再度情報の取得をし、状況(state)がJobCompleteになったら次へいく。Aborted/Failedの場合は処理を終了する。
3.クエリジョブの結果の取得(/services/data/vXX.X/jobs/query/queryJobId/results)
結果のCSVを取得(GET)。CSVファイルはUTF8エンコーディングされている。
クエリロケータを使って、次のレコードセットを取得していく。クエリロケータが文字列の"null"の場合は次のレコードセットはない。(クエリロケータが空のnullではなく、文字列で"null"と返ってくるのがポイント)
そして、APIの呼び出し毎に、ヘッダに列名が付与された状態のCSVが返却されるので、結果を1ファイルにまとめる場合、クエリロケータを指定した結果ではヘッダをスキップする必要がある。
SOQLの制限は次(2021年8月現在)
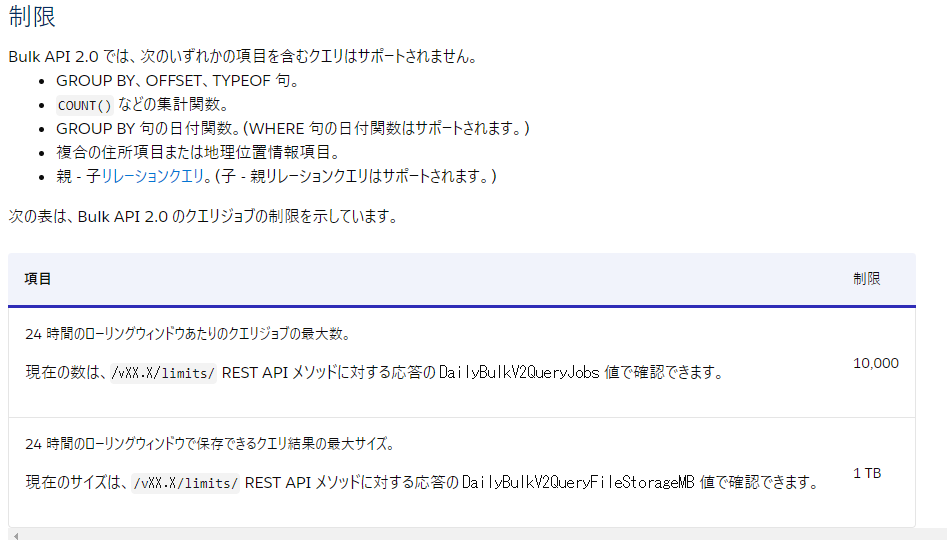
添付ファイル(Attachment)、ドキュメント(Document)、コンテンツバージョン(ContentVerson)など、Base64型の項目を持つオブジェクトはエラーとなりました。
複合項目(取引先の住所項目など)の項目をselectに含めるとエラーになりました。
Bulk API2.0での、一括アップロードの処理
まず、この処理はアップロードするCSVファイルをヘッダ付きで分割してあることが前提です。そしてアップロードするCSVファイルはUTF-8です。例えば、Shift_JISの100万件のCSVファイルを10万件ずつアップロードするには、ヘッダを付けて10万件ずつ分割し、UTF-8に変換して保存という事前処理が必要です。CSVには不要な列が入っているとエラーになります。
1.ジョブの作成(/services/data/vXX.X/jobs/ingest)
CSVの形式や、対象オブジェクト、オペレーション(insert/upsert/update/delete)などを指定する(POST)。CSVの形式は厳密であり、LFで指定したのに、CRLFとなっていたり、CRLFで指定したのにLFだった場合はエラーとなるので注意です。
2.ジョブデータのアップロード(/services/data/vXX.X/jobs/ingest/jobID/batches)
CSVをアップロードする(PUT)。もちろんGZIPしたほうが良いです。ただしくアップロードできたかは、HTTPのレスポンスコード201で判断する。
3.ジョブの終了または中止(/services/data/vXX.X/jobs/ingest/jobID)
stateをUploadCompleteにしてjson文字列を送信(PATCH)。
Javaで通常のHTTP通信でPATCHをするにはJDK11以上が必要になるので注意。PATCHさえなければ、すべてのHTTP通信がHttpURLConnectionで済んだのに。。
4.ジョブ情報の取得(/services/data/vXX.X/jobs/ingest/jobID)
ジョブの状況を取得する(GET)。定期的に状況を確認して、InProgressならば時間をあけてもう一度確認し、JobCompleteになるまで繰り返す。AbortedやFailedの場合は処理を中断する。
5.ジョブ成功レコードの結果の取得(/services/data/vXX.X/jobs/ingest/jobID/successfulResults/)
成功データを取得する(GET)。結果はUTF-8のCSVで、結果のSalesforceId(sf__Id)やタイムスタンプ(sf__Created)項目が追加される。結果がない場合でもヘッダ行のみ出力される。
6.ジョブ失敗レコードの結果の取得(/services/data/vXX.X/jobs/ingest/jobID/failedResults/)
エラーデータを取得する(GET)。結果はUTF-8のCSVで、エラー内容(sf__Error)やエラーレコードのSalesforceId(sf__Id)項目が追加される。結果がない場合でもヘッダ行のみ出力される。
CSVの値の形式は、次の特徴がありました。
・ヘッダ項目の大文字小文字の区別はない。(NameでもNAMEでも可)
・SOAP APIと異なりnull(空)で更新する場合は"#N/A"とする。(insert nullsの指定のオプションはない)
・参照項目/主従関係項目(以下参照項目で主従関係項目を含める)にID読み替えをする場合のヘッダの指定は、通常の参照項目は、「参照先名.IDルックアップ項目」で指定可能。
・複数の親オブジェクトを指定可能な参照項目にID読み替えをする場合、ヘッダにオブジェクトを含めることで指定可能「オブジェクト名:参照先名.IDルックアップ項目」です。
・Batch Sizeは指定できない。トリガの中でTrigger.Newのサイズは10までなどの制御を加えている場合、Batch Sizeへ10を指定できないので登録できない。
(データローダは外部ID項目のみですが、Bulk API2.0はIDルックアップ項目が使えます。IDルックアップ項目は例えば、ユーザオブジェクトのユーザ名や、メール、カスタムオブジェクトのName項目など外部IDの指定ができない項目を含みます。)
・日付の指定は「2021-08-15 」、日付/時間の項目は「2021-08-15T09:00:00.000Z」や「2021-08-15T18:00:00.000+0900」「2021-08-15T18:00:00.000+09:00」などデータローダでおなじみの形式です。データローダのタイムゾーンのオプションはない。
最後に
データエクスポートの速度、データのロード速度は通常のSOAP APIとは問題にならないくらい速いです。100万件ほどのデータなら10分もかからず処理することができます。
大分前の話ですが、Bulk API1.0の時はバッチジョブの制限が少なかったり、あまり使いやすいイメージがありませんでしたが、Bulk API2.0から使いやすくなっているなと感じました。(いつのまにかBulk API1.0の制限も今はBulk API2.0と同等になってました)
Salesforceからは標準ツールが用意されていないようなのでAPIを使って自作する必要があるのがハードルが高いなと思います。
数百万件など移行・連携があるときは積極的に使っていこうと思います。