公開グループ「すべての内部ユーザー」「すべてのパートナーユーザー」「すべてのカスタマーポータルユーザー」はデジタルエクスペリエンスを有効化後に使えます。
新しい組織で出てこないとなったときには、ここを確認します。
公開グループ「すべての内部ユーザー」「すべてのパートナーユーザー」「すべてのカスタマーポータルユーザー」はデジタルエクスペリエンスを有効化後に使えます。
新しい組織で出てこないとなったときには、ここを確認します。
自分用にあらためて整理した。
トリガテンプレート
trigger AccountTrigger on Account (before insert, before update, before delete, after insert, after update , after delete , after undelete) {
switch on Trigger.operationType {
when BEFORE_INSERT {
AccountTriggerHandler.onBeforeInsert(Trigger.New);
}
when BEFORE_UPDATE{
AccountTriggerHandler.onBeforeUpdate(Trigger.New, Trigger.Old);
}
when BEFORE_DELETE{
AccountTriggerHandler.onBeforeDelete(Trigger.Old);
}
when AFTER_INSERT{
AccountTriggerHandler.onAfterInsert(Trigger.New);
}
when AFTER_UPDATE{
AccountTriggerHandler.onAfterUpdate(Trigger.New,Trigger.Old);
}
when AFTER_DELETE{
AccountTriggerHandler.onAfterDelete(Trigger.Old);
}
when AFTER_UNDELETE {
AccountTriggerHandler.onAfterUnDelete(Trigger.New);
}
}
}
operationType を使うと Trigger.isNew Trigger.isBefore といったコンテキストの値を2つ使わなくてよくなる。
Before時:トリガーレコードの項目値の変更が可能、レコード毎にaddErrorでエラー制御が可能。
After時で、トリガーレコードの項目値は変更不可、レコード毎にaddErrorでエラー制御は不可(1レコードでもaddErrorするとそのトリガー内のレコードがエラー扱い。
処理上のポイント(自分的なもの)
Trigger.sizeは最大200、処理的な制約があり最大件数を制限する場合はbeforeトリガでサイズオーバーの場合はaddErrorする。
before insert と after insert で処理のポイントはafter insertでIdがセットされる
before update と after update で処理のポイントは、Trigger.NewとTrigger.Oldを比較することで処理を行う(値が変更された場合のみ処理を行う制御が可能)
before delete と after delete で処理のポイントは、after deleteでは、削除レコードを参照する子レコードの削除時の処理が実行されること(参照項目をクリアする場合は、子レコードの参照項目はクリアされる)、before deleteでもafter delete でもまだそのオブジェクトをselectするとレコードは取得できる。削除したレコードを除外する場合は明示的にwhere句で除外する。
カスケードデリートで削除された場合は、deleteトリガは実行されない。
カスケードデリートで削除されたレコードを参照する子レコードのトリガは実行されない。
網羅できているわけではないけど、たまに忘れるのでメモ。
Spring'24でLightningレコードページの動的フォームに機能が追加となり、参照先項目を表示できるようになりました。
参照先項目は2階層上のオブジェクトの項目まで可能です。
次の点で非常に便利だと思いました。
動的フォームでは、機能が多く
と非常に便利なのですが、どの項目を表示しているのか、どの条件で表示しているのかの確認に時間がかかるという印象を受けました。FlexiPageのメタデータも構造が複雑であるため何らかの工夫が必要なのだと感じています。
最新の情報に追い付いていなかったのであらためて記載する。
Spring'20
API 要求の日次上限 (1,000,000) が削除されました。
[API数の計算]
100,000 + (ライセンス数 x ライセンスの種類ごとのコール数) + 購入した API コールアドオン数
API数が増えてるのが嬉しいです。
Summer'20
プッシュ通知の制限が緩和されました
iOS プッシュ通知は組織ごとに 1 時間あたり最大 20,000 件、Android プッシュ通知は組織ごとに 1 時間あたり最大 10,000 件送信できます。
利用する機会がなかった機能ですが、制限あるということを覚えておこうと思います。
Winter'21
安全なナビゲーション演算子を使用した Null ポインタ例外の回避 ( ?. )
これは嬉しいです。これでApexとLWCでNullセールナビゲーションが使えるようになりました。
これで、NullPointerExceptionとはおさらばできると思いますが、むやみに使うと、今までエラーが発生して気づけたバグに気づけなくなるので注意です。
Auraでは使えないのがもどかしいです。
Apex からのカスタム通知の送信
Messaging.CustomNotification クラスを使用して、トリガなどの Apex コードから直接カスタム通知を作成、設定、送信します。
カスタム通知を使った仕組みを作りやすくなりました。テストクラスからは通知しないようにしないとエラーになるようでした。
Winter'23
同時に開くクエリカーソルの制限の削除
ユーザごとに同時に開くクエリカーソル数が制限されなくなりました。Apex 一括処理の start、execute、finish メソッドの結果セットも含まれます。
Visualforce画面で、StandardSetControllerをたくさん使っても安心です。(といっても、Lightning Componentを採用することがほとんどになってしまいましたが)
今まではカーソルが10まで、カーソルは15分以上放置するとエラーになるので使いづらかったです。
Spring'23
System.enqueueJob メソッドを使用したキュー可能ジョブのスケジュール遅延の指定
Integer delayInMinutes = 5;
ID jobID = System.enqueueJob(new MyQueueableClass(), delayInMinutes);
遅延実行は、今まではSystem.scheduleBatch しかなかったですが、Queueableでも遅延実行ができて便利になりました。System.scheduleBatchでは、同時にスケジュールされる Apex クラスの最大数100の制限、Queueableでは、Apex Flex キューに入っている Holding 状況の Apex 一括処理ジョブの最大数100の制限。
そして、24 時間あたりの非同期 Apex メソッド実行 (Apex 一括処理、future メソッド、キュー可能 Apex、およびスケジュール済み Apex) の最大数250000(組織内のユーザライセンス数 × 200 の大きい方の値)の制限は気を付ける必要があります。
Bulk API2.0で調べたことの続きです。
crmprogrammer38.hatenablog.com
Bulk APIでは、null更新時には、"#N/A"の値を指定する必要があります。
参照関係項目を外部ID指定で更新する時は、次のようにする必要がありました。
※参照関係項目と、参照先の外部IDの項目両方に値を指定するとエラーになります。

CSVに内容としては上記の通りとなります。例としてケースの親ケース(Parent)をケース番号で更新します。
親ケース番号で更新する行は、Parent.CaseNumber列に値を入れ、親ケースをnullで更新する行は、親ケース項目(ParentId)自体に、"#N/A"を指定します。
Salesforce内の件数の多いオブジェクトに対して、データの取得/登録/更新/削除を行う場合、通常のAPIのinsert/update/upsert/deleteでは時間がかかってしまうことがあります。
Salesforceでは、これに対してBulk API/Bulk API2.0を用意しており、Bulk API2.0について調べた結果の備忘メモです。
SOQLや、query/queryAllかなどを指定したjson文字列を送信(POST)
クエリジョブの状況を取得(GET)。状況(state)がInProgressならば、しばらく待って再度情報の取得をし、状況(state)がJobCompleteになったら次へいく。Aborted/Failedの場合は処理を終了する。
結果のCSVを取得(GET)。CSVファイルはUTF8エンコーディングされている。
クエリロケータを使って、次のレコードセットを取得していく。クエリロケータが文字列の"null"の場合は次のレコードセットはない。(クエリロケータが空のnullではなく、文字列で"null"と返ってくるのがポイント)
そして、APIの呼び出し毎に、ヘッダに列名が付与された状態のCSVが返却されるので、結果を1ファイルにまとめる場合、クエリロケータを指定した結果ではヘッダをスキップする必要がある。
SOQLの制限は次(2021年8月現在)
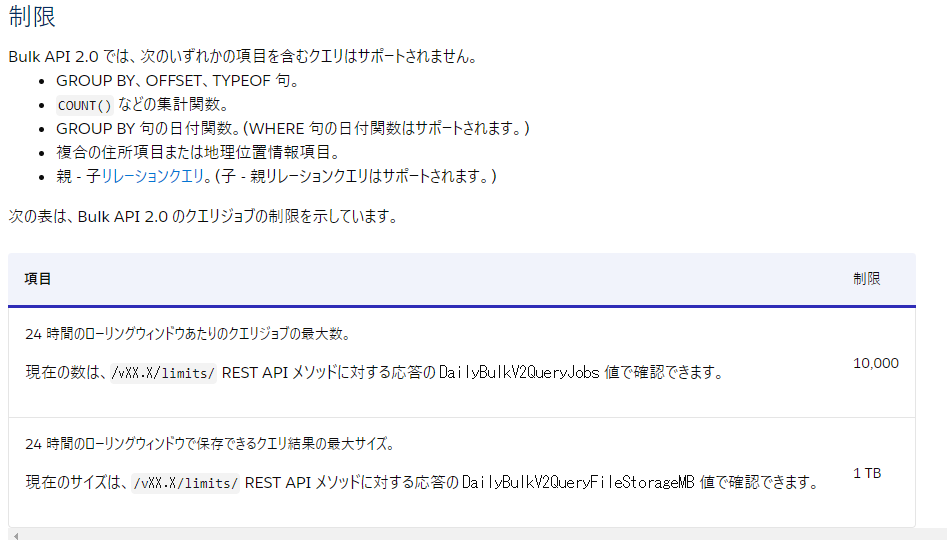
添付ファイル(Attachment)、ドキュメント(Document)、コンテンツバージョン(ContentVerson)など、Base64型の項目を持つオブジェクトはエラーとなりました。
複合項目(取引先の住所項目など)の項目をselectに含めるとエラーになりました。
まず、この処理はアップロードするCSVファイルをヘッダ付きで分割してあることが前提です。そしてアップロードするCSVファイルはUTF-8です。例えば、Shift_JISの100万件のCSVファイルを10万件ずつアップロードするには、ヘッダを付けて10万件ずつ分割し、UTF-8に変換して保存という事前処理が必要です。CSVには不要な列が入っているとエラーになります。
CSVの形式や、対象オブジェクト、オペレーション(insert/upsert/update/delete)などを指定する(POST)。CSVの形式は厳密であり、LFで指定したのに、CRLFとなっていたり、CRLFで指定したのにLFだった場合はエラーとなるので注意です。
CSVをアップロードする(PUT)。もちろんGZIPしたほうが良いです。ただしくアップロードできたかは、HTTPのレスポンスコード201で判断する。
stateをUploadCompleteにしてjson文字列を送信(PATCH)。
Javaで通常のHTTP通信でPATCHをするにはJDK11以上が必要になるので注意。PATCHさえなければ、すべてのHTTP通信がHttpURLConnectionで済んだのに。。
ジョブの状況を取得する(GET)。定期的に状況を確認して、InProgressならば時間をあけてもう一度確認し、JobCompleteになるまで繰り返す。AbortedやFailedの場合は処理を中断する。
成功データを取得する(GET)。結果はUTF-8のCSVで、結果のSalesforceId(sf__Id)やタイムスタンプ(sf__Created)項目が追加される。結果がない場合でもヘッダ行のみ出力される。
エラーデータを取得する(GET)。結果はUTF-8のCSVで、エラー内容(sf__Error)やエラーレコードのSalesforceId(sf__Id)項目が追加される。結果がない場合でもヘッダ行のみ出力される。
CSVの値の形式は、次の特徴がありました。
・ヘッダ項目の大文字小文字の区別はない。(NameでもNAMEでも可)
・SOAP APIと異なりnull(空)で更新する場合は"#N/A"とする。(insert nullsの指定のオプションはない)
・参照項目/主従関係項目(以下参照項目で主従関係項目を含める)にID読み替えをする場合のヘッダの指定は、通常の参照項目は、「参照先名.IDルックアップ項目」で指定可能。
・複数の親オブジェクトを指定可能な参照項目にID読み替えをする場合、ヘッダにオブジェクトを含めることで指定可能「オブジェクト名:参照先名.IDルックアップ項目」です。
・Batch Sizeは指定できない。トリガの中でTrigger.Newのサイズは10までなどの制御を加えている場合、Batch Sizeへ10を指定できないので登録できない。
(データローダは外部ID項目のみですが、Bulk API2.0はIDルックアップ項目が使えます。IDルックアップ項目は例えば、ユーザオブジェクトのユーザ名や、メール、カスタムオブジェクトのName項目など外部IDの指定ができない項目を含みます。)
・日付の指定は「2021-08-15 」、日付/時間の項目は「2021-08-15T09:00:00.000Z」や「2021-08-15T18:00:00.000+0900」「2021-08-15T18:00:00.000+09:00」などデータローダでおなじみの形式です。データローダのタイムゾーンのオプションはない。
データエクスポートの速度、データのロード速度は通常のSOAP APIとは問題にならないくらい速いです。100万件ほどのデータなら10分もかからず処理することができます。
大分前の話ですが、Bulk API1.0の時はバッチジョブの制限が少なかったり、あまり使いやすいイメージがありませんでしたが、Bulk API2.0から使いやすくなっているなと感じました。(いつのまにかBulk API1.0の制限も今はBulk API2.0と同等になってました)
Salesforceからは標準ツールが用意されていないようなのでAPIを使って自作する必要があるのがハードルが高いなと思います。
数百万件など移行・連携があるときは積極的に使っていこうと思います。